所以,我们现在的目标非常明确:我们要融合这两种力量。我们要将基于规则的数值模拟(那是我们对物理世界的深刻理解)与基于数据的机器学习(那是处理复杂性的高效工具)结合起来。我们要创造一种“基于物理的非参数化AI”(NPP-AI,Non-parametric physics based AI)。这听起来可能有点拗口,但请相信我,这是通往未来的钥匙。
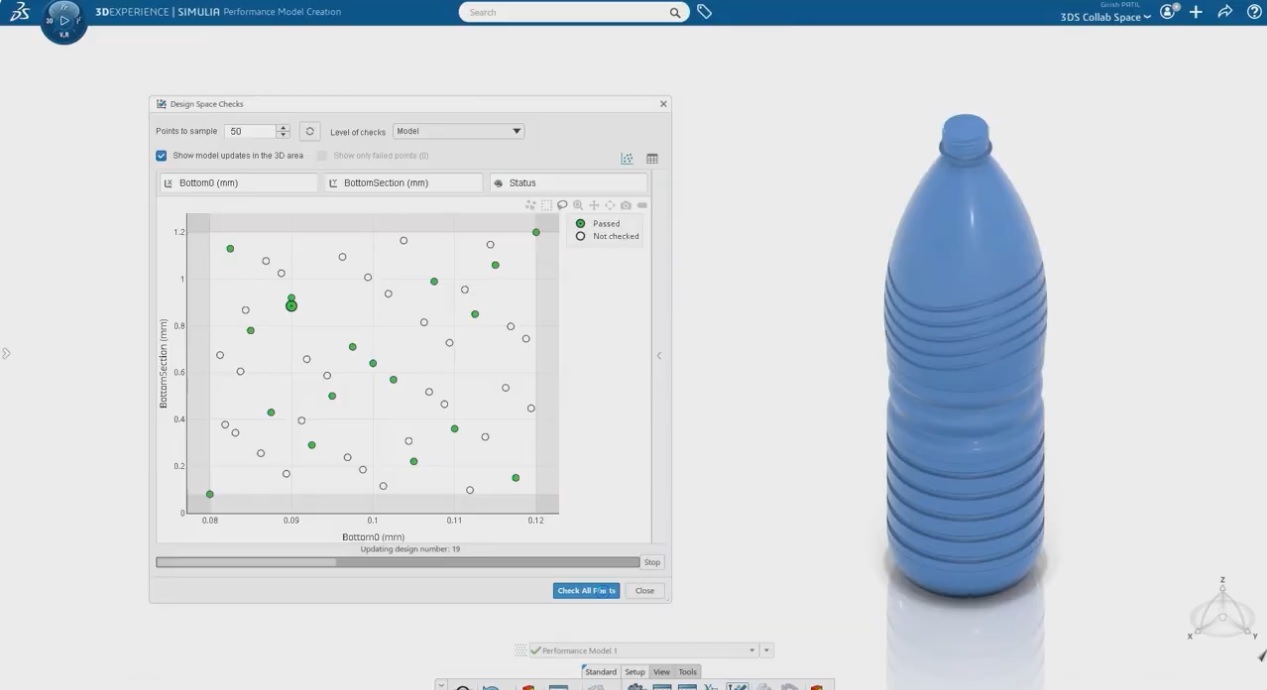
但是,物理学告诉我们,流体流过第一代瓣膜所遵循的规律,和流过第十代瓣膜所遵从的规律,是完全一样的。纳维-斯托克斯方程不会因为你的产品型号变了就改变。
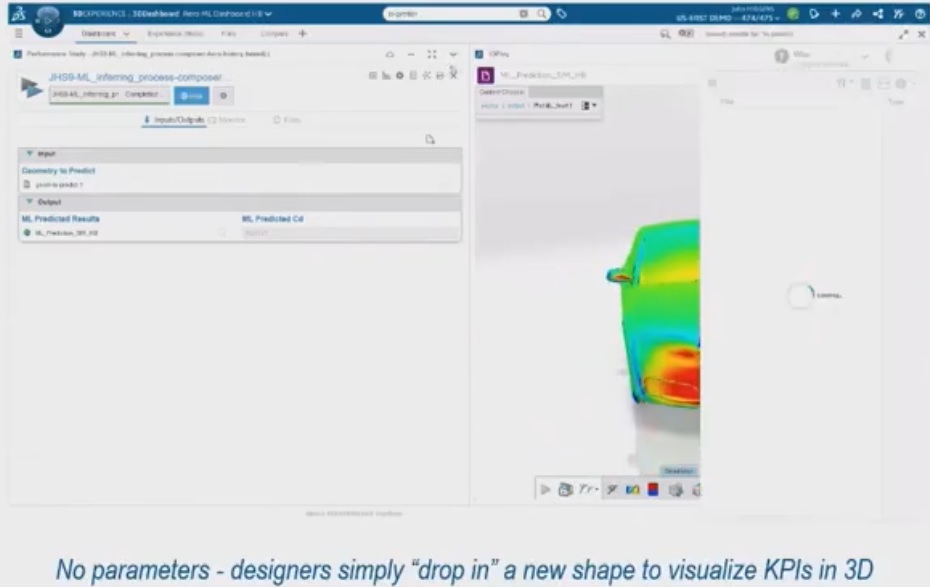
通过非参数化AI,我们正在构建一种“企业级基础模型”(Enterprise Foundation Model)。我们可以把一家公司过去二十年所有的历史数据——不管是圆的、扁的、长的、短的设备设计——全部扔进去训练。AI不看参数,它看形状的本质。
这样,我们就训练出了一个“懂瓣膜”的AI。它不仅仅是记住了某个特定型号的数据,它提取了关于“人工瓣膜”这个概念的普遍知识。当你开始设计未来的第十一代产品时,你不再是从零开始。你拥有了一个包含了整个企业历史智慧的大脑在辅助你。这种知识的提取和复用,将把新产品的研发周期从几年缩短到几个月。历史数据不再是负担,而是最宝贵的资产。
Nicolas Pecuchet:Jing,非常精彩的演讲。这里展示的技术深度令人印象深刻。我有一个关于预测能力的问题。在多参数或多物理过程的设计中,我理解潜在空间可以生成匹配全3D DNS(直接数值模拟)的机器学习解。
但是,如果我放入的是一段历史,本质上是一个具有时间依赖性的过程,从时刻0到最终时刻。如果我把预测的时间点固定在时刻t。通过这套流程,你是否能够信任它产生的预测,不仅是验证当前状态,而是去预测t加上未来某个时间的状况?换句话说,这个机器学习模型能否不仅做验证,还能做‘天气预报’式的未来预测,并回头检查它是否匹配我们已有的物理仿真时间序列?”
 |小黑屋|手机版|Archiver|机械荟萃山庄
( 辽ICP备16011317号-1 )
|小黑屋|手机版|Archiver|机械荟萃山庄
( 辽ICP备16011317号-1 )



 发表于 2026-1-27 10:10:03
发表于 2026-1-27 10:10:03