一个有趣的例子是IsaacJinyu在知乎的一次AI卧底实验,他通过知乎问答数据反向生成AI数据,然后微调Qwen2-7B,去除文字中的AI味。这个实验从7月5日开始,到8月3日整整一个月,没有任何人发现账号AI的身份。
日益增多的AI生成内容其影响远不止于屏幕,这种潜移默化的侵入正悄然影响学术领域。
进年初,西安交大一篇论文因为使用AI生成的配图而被撤稿,相关图片中,大鼠长出了诡异的器官,细胞信号传导图像电路板。
在另一篇论文的一张配图中,小腿和手臂的骨骼数量出现了明显的错误。
这只是AI渗透学术领域的冰山一角,在谷歌学术上搜索“截至我上次知识更新”(as of my last knowledge update)或“我没有访问实时数据的权限”(I don't have access to real time data),会出现大量借助AI生成的论文。
学者们在压力之下需在期刊上发表论文,选择了使用AI,而学生在AI的帮助下完成作业和论文已经成为一种常态,“人工代写”论文变成了“人工智能”代写。
 |小黑屋|手机版|Archiver|机械荟萃山庄
( 辽ICP备16011317号-1 )
|小黑屋|手机版|Archiver|机械荟萃山庄
( 辽ICP备16011317号-1 )



 发表于 2024-9-25 15:02:22
发表于 2024-9-25 15:02:22


 发表于 2024-9-25 15:08:04
发表于 2024-9-25 15:08:04
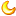
 发表于 2024-9-25 18:36:46
发表于 2024-9-25 18:36:46